自社のデータプラットフォームを
AIと一体化させる
現在のIBM戦略は、「Watson Data & AI」という言葉に体現されている。2018年3月に米ラスベガスで開催された「IBM Think 2018」でも、また同年6月に東京で開催された「IBM Think Japan 2018」でも、「Watson Data & AI」が強くメッセージされていた。
データとAI。どちらの言葉もとくに目新しくはないが、IBMが敢えてこの言葉を使って表現するメッセージを紐解くなら、「個々の企業が所有する多種多様で膨大、かつ未活用のデータを、AIにより、ナレッジや知見に変えて活用すること」になる。このメッセージが示唆するように、企業は今後、自社のデータプラットフォームとAIを完全に一体化させる方向へ進んでいくことになるだろう。
その戦略を具現化するために、Watsonのラインナップには大きな変化が見られる。
図表1は、IBM Cloudで提供されているWatson APIおよびサービスの一覧である。これらは大きく2つに分けられる。1つは業界・業種向けに事前学習(プリトレーニング)し、自社業務へAIを迅速に適用可能にする一連のAPI群。もう1つは、企業独自のAIソリューションを作成するための統合開発・分析環境および継続学習基盤である。

Watson APIは現在、「照会応答」「知識探索」「画像」「音声」「言語」の各領域で、合計12種類が提供されている(うち2種類は日本語未対応)。このなかで大きく拡充されているのが、「照会応答」と「知識探索」の分野である。
「照会応答」では、チャットボットやコールセンター支援に代表される照会応答系システムの構築を支援する「Watson Assistant」(以下、Assistant)が2018年3月に、「Watson Conversation」から名称を変更し、新たな機能を追加してリリースされた。機械学習や自然言語解析の技術を使用し、ユーザーが自然言語で質問すると、適切な応答を返す対話アプリケーションを構築する。
Assistantでは、顧客が会話の途中で無関係な質問を発したとき、それに対応して別の会話を開始したり、元の会話に戻ったりする「脱線」機能(Digressions)や、ユースケースに特化した学習済みインテントの提供、分析用ダッシュボードの拡張、後述する「Watson Studio」との連携により本番環境を想定したシミュレーションや会話ログ分析を実行する機能などが新たにサポートされている。
Discoveryのエンリッチメント
確かな洞察・知見を導く
一方、知識探索系のAPIでは、「Watson Discovery Service」(以下、Discovery)が注目されている(2016年12月にリリース、2017年9月末に日本語化、2018年6月に日本語がフルサポートされた)。
Discoveryは、構造化および非構造化データを含めた大量のデータを照会して洞察・知見を導く、一言で言えば「AIライクな照会・検索エンジン」である。
Discoveryでは自然言語による検索が可能で、人間が気づかない価値、隠れた相関や関係性をデータから発見するために、検索や回答の精度を高めるための仕組みを備えている。これが「エンリッチメント」である。
たとえば非構造化データである人間の会話や文章から、興味や調査の対象となるフィールドを抽出し、元のデータに追加する(これを「アノテーション」と呼ぶ)。こうすれば、文章に対する全文検索だけでなく、構造化データと同じように、抽出したフィールドによる検索が可能になる。つまり、元データをエンリッチ(豊か)にして、照会・検索の能力を高めるのである。
Discoveryのエンリッチメントには、大きく2種類ある。「Natural Language Understanding」(以下、NLU)による標準エンリッチメントと、「Watson Knowledge Studio」(2017年12月にIBM Cloud上のサービスとして追加。以下、WKS)によるカスタム・エンリッチメント である。
NLUはWatson APIであり、単独でも使用できる。DiscoveryはNLUを内蔵しているので、Discoveryでエンリッチメントの方法を指定しておけば、内部的に自動実行する。
ただしNLUでは、興味や調査の対象としてエンリッチするフィールドを、自由にカスタマイズできない。これを可能にするのが、WKSである。WKSは情報抽出のための機械学習モデル(アノテーター)を作成し、これを Discovery(もしくはWatson Explorerなど他のWatson製品)に取り込んで、カスタマイズされたエンリッチメントを可能にする。
Watson Studio
AIの統合開発・分析環境
一方、企業独自のAIソリューションを作成する統合開発環境および継続学習基盤として注目されるのが、「Watson Stu
dio」や「Watson Knowledge Catalog」、それに「Watson Machine Learning」である(図表2)。
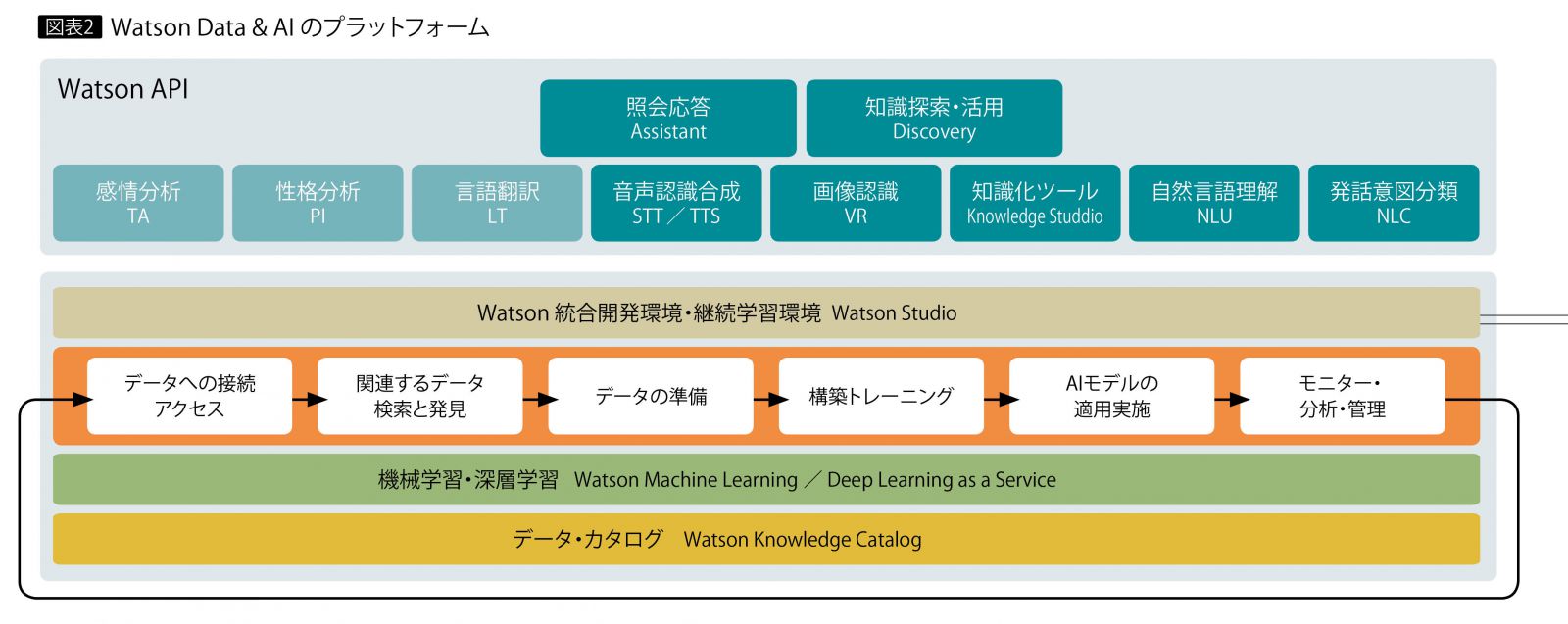
現在、多くの企業が自社の業務や独自性を反映したAIソリューションの開発に取り組んでおり、プロジェクトの規模や数は急速に増えつつある。こうしたAIプロジェクトには、業務の専門家やデータサイエンティスト、システム部門の開発者など多彩なメンバーが参加する。そこでAIソリューション構築に向けたチーム開発の生産性向上を目的に提供されているのが、Watson Studioである。
Watson Studioは以前、「Watson Data Platform」と呼ばれるデータ分析プラットフォームのもとで提供されていた「Data Science Experience」(DSX)や「Watson Machine Learning Service」(WML)などのサービス群を整理・統合し、新たな機能を追加したオールインワン型の統合開発・分析環境である。
AI モデルの構築、トレーニング、デプロイ、管理から、データの準備・分析に至るまでプロジェクトの全ライフサイクルをサポートし、ツール間の連携や、アセットおよび成果物の共有など、チームのコラボレーションを円滑に進めるための機能を搭載する。
SPSS Modelerなどのデータ分析機能に加え、Apache SparkやR言語、Jupyter、Caffe、Torchといったオープンソース系の言語やフレームワークなどを数多く統合しているので、各々の担当者が目的と役割に応じた最適ツールを選択できる。
またWatson APIを簡単に利用可能にするユーザーインターフェースが提供されている。これらはすべてIBM Cloud上で利用可能。以下に、Watson Studioがサポートする代表的な機能を挙げる。
・データの準備や加工(Refine Data)
・Jupyter Notebookによるデータ分析
・マシンラーニングのモデル作成
・ディープラーニングのモデル作成(Deep Learning as a Service)
・画像認識のためのトレーニング
・分析結果を共有するダッシュボード
・SPSS Modelerによるデータ分析
・IoTストリーミングデータの分析
・Watson APIとの統合
Knowledge Catalog
AI Readyなデータ・カタログ
またWatson Studioと密接に連携したデータ・カタログ基盤が、「Watson Knowledge Catalog」(以下、Knowledge Cata
log)である。2018年3月、「IBM Data Catalog」から名称変更され、各種機能を拡張している。
企業が取り組むAIプロジェクトでの大きな課題は、データ整備作業に多大な工数を要することである。
「AIプロジェクト工数の約80%が、データソースからの収集・探索・加工、学習データの準備といったデータの整備に費やされています。これらの作業をどれだけ最小化できるかが、開発生産性を大きく左右することになります。そこで企業内のどこに、どういったデータがあるかをメタ情報とともにカタログ化し、すぐに使える状態に整備するのがKnowled
ge Catalogの役割です。これは、強力なデータ・ガバナンスを実現するAI Readyなデータ・カタログであると考えてください」と、日本アイ・ビー・エムの溝渕浩章氏(ワトソン事業部 テクニカル・ソリューション担当)は指摘する。

Knowledge Catalogでは、企業のオンプレミスで管理されるデータソースのみならず、IBM Cloud上、さらに他社のクラウドサービス上にあるデータもデータ・カタログの対象にできる。
また同じくWatson Studioと連携するという観点では、「Watson Machine Learning」(以下、WML)も注目される。2016年にSPSSベースのスコアリングサービス「Predictive Analytics」から改称し、さまざまな機能強化を図ってきた。
WMLはIBM Cloud上で機械学習モデルを作成し、さまざまな予測を導き出す。Watson Studioのユーザーインターフェースから利用することも、APIによりアプリケーションに組み込むことも可能。データサイエンティストや業務担当者など、ITの専門スキルをもたなくても、品質・性能の高い予測分析モデルを迅速かつ簡単に作れるのが特徴である。
WMLでは、データ分析プロジェクトのチーム支援を目的に、機械学習のモデル作成から性能評価、デプロイ、スコアリング、フィードバックまでの全ライフサイクルをサポートする。
本番デプロイ後のモデル性能を継続的にモニターし、劣化した(事前に設定した閾値を下回った)場合は、新しいデータで再トレーニングし、新しいモデルのほうが優れていれば再デプロイするという「継続的学習」(Continuous Learning)を実行できる点も大きな特徴である。これはWMLのなかで、「継続的学習システム」(Continuous Learning System)と呼ばれる機能としてサポートされている。
予測分析モデルは本番デプロイ後、長期にわたって同じモデルを利用し続けると、さまざまな外部要因の変化によって精度が低下し、正確な予測を得られなくなる。そこでモデルの劣化を防ぐため、定期的かつ自動的に、新しいデータによってモデルを再構築していく継続的学習の仕組みが、実運用には不可欠となる。
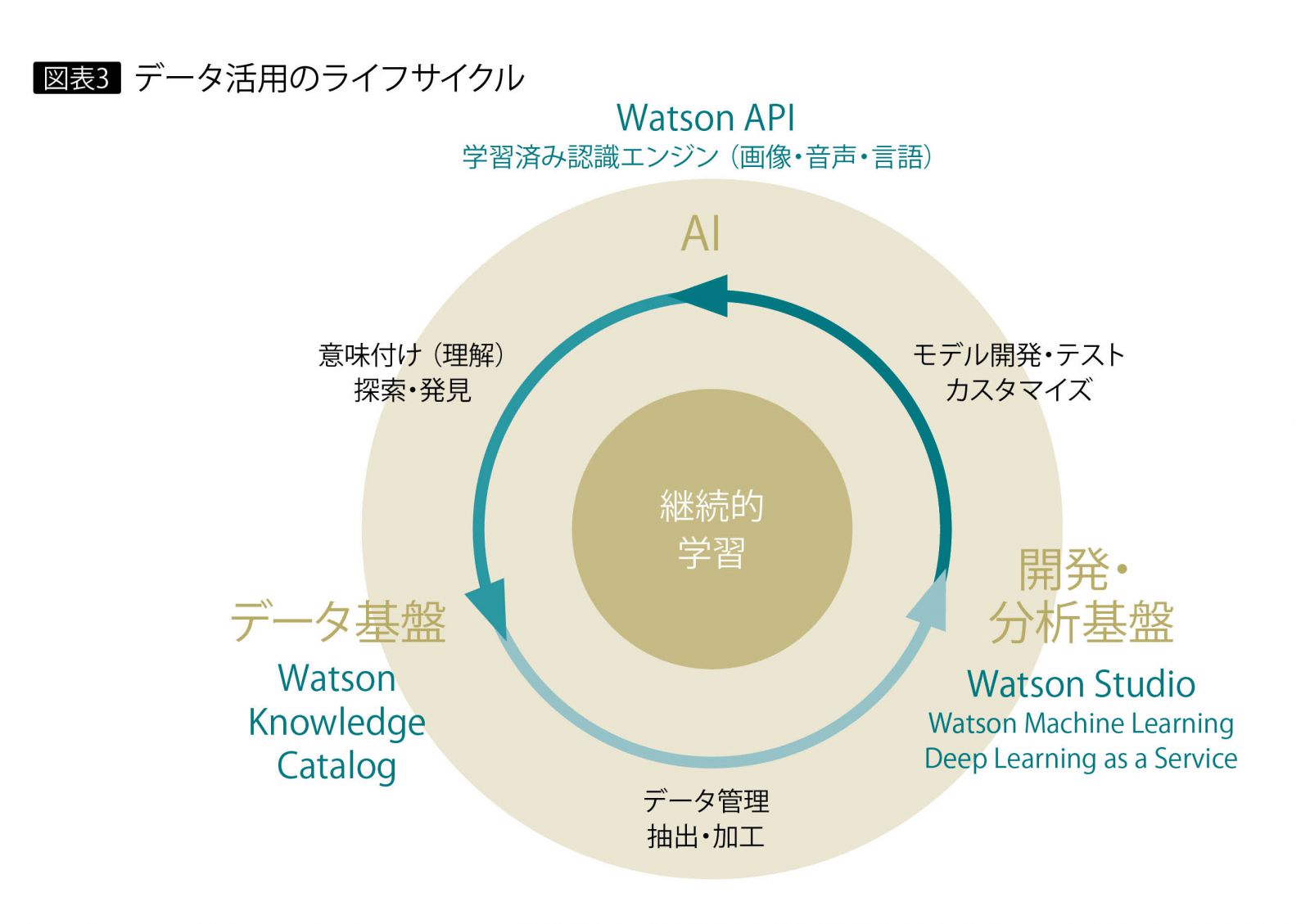
このように継続的学習を軸に、学習済み認識エンジンであるWatson API、データ基盤であるKnowledge Studio、そして開発・分析基盤であるWatson Studioの各プロセスを循環させることで、IBMが提唱する「Watson Data & AI」のデータ活用ライフサイクルが形成されることになる(図表3)。
AIの業務適用の拡大、データプラットフォームとの一体化、そしてAIプロジェクトの増大を背景に、Watsonはさまざまな機能強化により進化を続けている。
[IS magazine No.20 (2018年7月)掲載]
●特集|Watson Update
Part 1
Watson API&サービスの進化の方向性を探る ~データプラットフォームとAIの完全一体化に向けたロードマップ
Part 2
Watson Knowledge Studio ~機械学習とルールベースで業界固有の用語や表現をWatsonに教える
Part 3
Watson Discovery Service ~質問と回答の類似性に焦点を当て、回答候補をランキング提示する
Part 4
Watson + RPA ~データの種類と複雑性を軸にWatsonが判断し、後続のRPAを動かす